MySQL은 다양한 내장 함수를 포함하고 있다.
내장함수의 종류
| 숫자 함수(수학 함수) | 문자열 함수 | 날짜/시간 함수 | 제어 흐름 함수 |
| 전체 테스트 검색 함수 | 형 변환 함수 | XML 함수 | 비트 함수 |
| 보안/압축 함수 | 정보 함수 | 공간 분석 함수 | 기타 함수 |
-> 이외에도 많이 있지만 필요할 때마다 검색해서 보는 걸로..!
1. 숫자함수(Number Functions)
| ABC(n) | 절대값을 구한다. |
| CEIL(n), CEILING(n) | 값보다 큰 정수 중 가장 작은 정수를 구한다. 소수점 이하 올림 |
| FLOOR(n) | 값보다 작은 정수 중 가장 정수를 구한다. 소수점 이하 버림 |
| ROUND(n, 자릿수) | 자릿수를 기준으로 반올림 |
| TRUNCATE(n, 자릿수) | 자릿수를 기준으로 버림 |
| POW(X, Y), POWER(X, Y) | X의 Y승 |
| MOD(분자, 분모) | 분자를 분모로 나머지 구하기 |
| GREATEST(n1, n2, n3..) | 주어진 숫자 중에 가장 큰 값을 반환 |
| LASTEST(n1, n2, n3…) | 주어진 숫자 중에 가장 작은 값을 반환 |
1) ABS(숫자) absolute – 절대값
- 절대값을 계산하는 함수(무조건양수로 만든다.)
Mysql> SELECT ABS(10), ABS(-10);

2) CEIL(숫자), CELING(숫자) – 올림
- 주어진 값보다는 크지만 가장 근접하는 최소값을 구하는 함수
Mysql> SELECT CEIL(10.1), CEILING(-10.1);
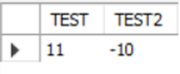
CEIL(10.1) 무조건 11
CEIL(-10.1) -11보다 -10이 더 커서 -10
3) MOD(숫자1, 숫자2), %, MOD – 나머지
MOD 나머지 구하기(숫자1을 숫자2로 나눈 나머지 값)
Mysql> SELECT MOD(14,3), 14%3, 14 MOD 3;

4) FLOOR(n) 내림
주어진 값보다 작거나 같은 최대 정수 값을 구하는 함수
Mysql> SELECT FLOOR(10.9), FLOOR(-10.1);

5) ROUND(n, [m])
ROUND함수는 n값의 반올림을 하는 함수로 m(양수일 경우 소수이하, 음수일 경우 정수부분)은 소수점 아래 자릿수를 나타낸다.
Mysql> SELECT ROUND(191.123,1);
Mysql> SELECT ROUND(192.123, -1);
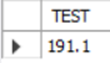
-- 소수이하 첫 번째 자리로 반올림
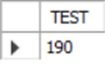
-- 정수부분 첫 번째 자리를 두 번째 자리로 반올림
6) RAND – 0과 1사이의 난수
RAND( )는 0이상 1 미만의 실수(무작위)를 구한다. 만약 'm<= 임의의 정수 <n'을 구하고 싶다면 FLOOR(m + RAND()* (n-m))을 사용하면 된다.
Mysql> SELECT CEIL(RAND()*11); -- 1 ~ 11까지의 숫자 출력
Mysql> SELECT CEIL(RAND()*100); -- 1 ~ 100까지의 숫자 출력
Mysql> SELECT FLOOR(RAND()*6)+1 -- 1 ~ 6까지의 숫자 출력
7) POW(m, n), SQRT(n) – 거듭제곱, 제곱근
POWER함수는 m의 n승 값을 계산한다.
Mysql> SELECT POW(4,2);
=> 4의 2승: 16
8) FORMAT(숫자, 소수점 자릿수)
숫자를 소수점 아래 자릿수까지만 표현한다. 1000단위마다 콤마로 표시한다.
Mysql> SELECT FORMAT(123.1234, 2);
=> 123.12
MySql> SELECT FORMAT(123.1634, 1);
=> 123.2
2. 문자열 처리 함수(Character Functions)
1) ASCII CHAR
ASCII(s)
- ASCII는 문자의 아스키 코드값을 반환한다.
CHAR(65)
CHAR은 아스키 코드 값에 해당하는 문장을 반환한다.
Mysql> SELECT ASCII('A'), CHAR(65);

2) BIT_LENGTH, CHAR_LENGTH, LENGTH
| bit_length | BIT 크기 | char_length | 문자수 | length | 할당된 BYTE 크기 |
Mysql> SELECT BIT_LENGTH('abc'), CHAR_LENGTH('abc'), LENGTH('abc');
Mysql> SELECT BIT_LENGTH('가나다'), CHAR_LENGTH('가나다'), LENGTH('가나다');


-> 한글은 문자당 3바이트(1바이트:8비트, 3바이트:24비트)
3) CONCAT
CONCAT(문자열1, 문자열2)
CONCAT은 문자열을 이을 때 사용한다.
CONCAT_WS는 구분자와 함께 문자열을 이을 때 사용한다.
Mysql> SELECT CONCAT ('안녕','내이름은','sql'), CONCAT_WS ('- ','안녕','내이름은','sql');
Mysql> SELECT CONCAT(first_name, last_name) , CONCAT_WS(' ', first_name, last_name) FROM employees;


4) ELT, FIELD, FIND_IN_SET, INSTR, LOCATE
| ELT(위치, 문자열, 문자열, …) | 위치 번째의 문자를 반환 |
| FIELD(찾을 문자열, 문자열,…) | 찾을 문자열의 위치를 찾아서 있으면 위치를, 없으면 0을 반환 |
| FIND_IN_SET(찾을 문자열, ‘문자,문자,문자’,..) |
찾을 문자열을 문자열 리스트에서 찾아서 위치를 반환 문자열 리스트는 콤마(,)로 구분되어 있어야 하고 공백이 없어야 함 |
| INSTR(기준문자열, 부분문자열) | 기준 문자열에서 부분 문자열을 찾아서 그 시작 위치를 반환 |
| LOCATE(부분문자열, 기준문자열) | INSTR와 동일하지만 파라미터의 순서가 반대로 되어있음 |
Mysql> SELECT ELT(3, 'ab','bb','bc') , FIELD('ab','ab','bb','bc'), FIND_IN_SET('ab','ab,bb,bc'),
INSTR('abcd','b'), LOCATE('b','abcd');

5) INSERT
INSERT(기준 문자열, 위치, 길이, 삽입할 문자열)
- 기준 문자열의 위치부터 길이만큼을 삽입할 문자열로 변경한다.
Mysql> SELECT INSERT('가나다라마', 2 , 3 ,'@@@'), INSERT('가나다라마', 1, 4, '####');

6) REVERSE
- 문자열을 거꾸로 만든다.
Mysql> SELECT REVERSE('가나다라마바');

7) LEFT and RIGHT
LIFT(문자열, 길이): LEFT는 문자열의 왼쪽부터 길이만큼 반환한다.
RIGHT(문자열, 길이): RIGHT는 문자열의 오른쪽부터 길이만큼 반환한다.
Mysql> SELECT LEFT(first_name, 2), RIGHT(first_name, 2), first_name FROM employees;

8) LCASE UCASE
LCASE: 대문자를 소문자로 변경한 후 반환한다.
UCASE: 소문자를 대문자로 변경한 후 반환한다.
Mysql> SELECT LCASE(first_name), UCASE(first_name), first_name FROM employees;

9) LPAD RPAD
- LPAD(문자열, 길이, 채울 문자열)
- 왼쪽에 채울 문자열을 끼어 넣는 역할
- 문자열을 전체 길이만큼 늘린 후에, 빈 곳을 채울 문자열로 채운다.
- RPAD(문자열, 길이, 채울 문자열)
- LPAD와 반대로 오른쪽에 채울 문자열을 끼어 넣는 역할을 한다.
Mysql>SELECT LPADE(first_name, 10, '*'), RPAD(first_name, 10, '-'), first_name FROM employees;

10) SUBSTRING
- SUBSTRING(문자열, 시작위치, 길이)
- 시작 위치부터 길이만큼 문자를 반환한다. 길이가 생략되면 문자열의 끝까지 반환한다.
Mysql> SELECT SUBSTRING(first_name, 2, 3), first_name FROM employees;
- SUBSTRING_INDEX(문자열, 구분자, 횟수)
- 문자열에서 구분자가 왼쪽부터 횟수 번째 나오면 그 이후의 오른쪽은 버린다. 횟수가 음수면 오른쪽부터 세고 왼쪽을 버린다.
Mysql> SELECT SUBSTRING_INDEX('gid1106.naver.com', '.', - 2) substring,
SUBSTRING_INDEX('gid1106.naver.com', '.', 2) substring2;


[중간문제]
이름을 글자길이의 50%만큼 출력하고 나머지 문자는 ‘*’으로 표시하라.(first_name 이용)
-- abcdef -> abc***
-- abcde -> ab***, abc**
Mysql> SELECT first_name, char_length(first_name),
rpad(substring(first_name, 1, (char_length(first_name)/2)), char_length(first_name) ,'*') FROM employees;
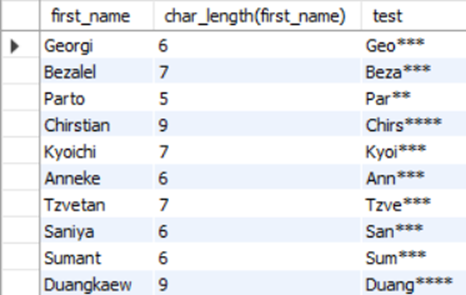
Mysql> SELECT first_name, char_length(first_name),
rpad(substring(first_name, 1, floor(char_length(first_name)/2)), char_length(first_name) ,'*') FROM employees;
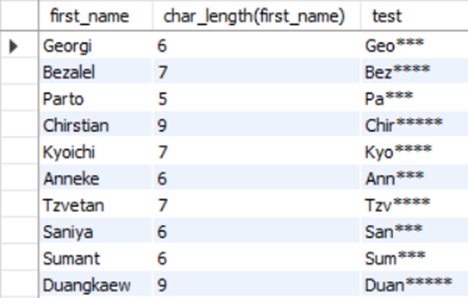
11) REPEAT(문자열, 횟수)
- 문자열을 횟수만큼 반복
Mysql> SELECT REPEAT('abc', 3);

12) REPLACE
REPLACE(문자열, 원래 문자열, 바꿀 문자열)
- 문자열의 특정 문자를 다른 문자로 변환한다.
- 대소문자 구별한다.
Mysql > SELECT first_name, REPLACE(first_name, 'a', '에이'), REPLACE(first_name, 'A', '에이') FROM employees ORDER BY first_name asc;
Mysql> SELECT REPLACE('이것은 책이다','책','book');


13) LTRIM, RTRIM, TRIM
- 특정한 문자를 제거한다.
| TRIM(문자열) | 문자열의 앞뒤 공백을 모두 없앤다. |
| TRIM(방향 자를_문자열 FROM 문자열) | 방향은 LEADING(앞), BOTH(양쪽), TRAILING(뒤)가 나올 수 있다. |
| LTRIM(문자열) RTRIM(문자열) | 문자열의 왼쪽/오른쪽 공백을 제거한다. 중간의 공백은 제거불가 |
Mysql> SELECT TRIM(' 이것은 mysql이다. '), LTRIM(' 이것은'), RTRIM('mysql이다. ‘);

3. 날짜 및 시간 함수
* 현재 시스템의 날짜와 시간을 구하는 함수 *
| CURDATE( ) | 현재 년-월-일을 반환 |
| CURTIME( ) | 현재 시-분-초를 반환 |
| NOW( ) | 년-월-일 시:분:초를 반환 |
| SYSDATE( ) | 년-월-일 시:분:초를 반환 |
| DATE() | 날짜와 시간에서 년-월-일을 반환 |
| TIME() | 날짜와 시간에서 시:분:초를 반환 |
Mysql> SELECT CURDATE(), CURTIME(), NOW(), SYSDATE();

Mysql> SELECT date(NOW()), time(SYSDATE());

* 날짜 데이터에서 특정 년, 월, 일, 시, 분, 초, 밀리초를 구하는 함수 *
| YEAR(NOW()) | MONTH(NOW()) | DAYOFMONTH(NOW()) | HOUR(NOW()) |
| MINUTE(NOW()) | SECOND(NOW()) | MICROSECOND(NOW()) |
Mysql> SELECT YEAR(NOW()), MONTH(NOW()), DAYOFMONTH(NOW()),
HOUR(NOW()), MINUTE(NOW()), SECOND(NOW()), MICROSECOND(NOW());

Year, Month, DayOfMonth로 각 년도와 월, 일 추출
Mysql> SELECT YEAR(NOW()), YEAR(SYSDATE()), YEAR(CURDATE());
Mysql> SELECT MONTH(NOW()), MONTH(SYSDATE()), MONTH(CURDATE());
Mysql> SELECT DAYOFMONTH(NOW()), DAYOFMONTH(SYSDATE()), DAYOFMONTH(CURDATE());



3) ADDDATE SUBDATE
ADDDATE(날짜, 차이)
- 날짜를 기준으로 차이를 더한 날짜를 변환한다.
SUBDATE(날짜, 차이)
- 날짜를 기준으로 차이를 뺀 날짜를 반환한다.
Mysql> SELECT ADDDATE(NOW(), INTERVAL 31 DAY), SUBDATE(NOW(), INTERVAL 31 DAY);
Mysql> SELECT ADDDATE(NOW(), INTERVAL 10 DAY), SUBDATE(NOW(), INTERVAL 10 DAY);

adddate를 하면 한 달 후, subdate하면 한 달 전

4) DATEIFF TIMEDIFF
DATEIFF(날짜1, 날짜2),
-> 날짜1 – 날짜2의 일수를 결과로 구한다. (날짜2에서 날짜1까지 몇 일이 남았는지 구한다.)
TIMEDIFF(날짜 또는 시간1, 날짜1 또는 시간2)
-> 시간 1 – 시간 2의 결과를 구한다.
Mysql> SELECT DATEDIFF('2022,01,15', '2022,01,05') DATEDIFF, TIMEDIFF('12:00:00', '10:00:00') TIMEDIFF;

5) DAYOFWEEK MONTHNAME DAYOFYEAR
| DAYOFWEEK(날짜) | 요일을(1:일, 2:월~7:토) |
| MONTHNAME(날짜) | 해당 월의 영어이름 반환 |
| DAYOFYEAR(날짜) | 1년 중 몇 일이 지났는지를 반환 |
Mysql> SELECT DAYOFWEEK('2022-01-01'), MONTHNAME('2022-01-01'), DAYOFYEAR('2022-01-01');

6) LAST_DAY TIME_TO_SEC
LAST_DAY(날짜): 주어진 월의 마지막날을 반환
TIME_TO_SEC(시간): 시간을 초 단위 반환
Mysql> SELECT LAST_DAY('2022,12,01');
Mysql> SELECT TIME_TO_SEC('12:00:00');


4. 변환 함수(Conversion Functions)
1) CAST
CAST(표현할 값 AS 데이터형식[(길이)]: 표현할 값을 해당 데이터 형식으로 바꾸는 것
Mysql> SELECT CAST('2022.01.01' AS DATE), CAST('2022,01,01' AS DATE), CAST('2022$01,01' AS DATE);

2) DATE_FORMAT(날짜시간, 포맷형식)
| %Y | 4자리연도 | %y | 2자리 연도 |
| %M | 월명을 영어이름 | %m | 2자리(00-12) |
| %d | 일 2자리(00-31) | %D | 일 1ST,2ND |
| %H | 시(24시간 형식, 00-23) | %h | 시(12시간 형식, 00-12) |
| %i | 분(2자리, 00-59) | %s, %S | 초(2자리, 00-59) |
| %f | 100만분의 초(마이크로 초) | %T | 시분초(24시간 형식, hh:mm:ss) |
| %p | 오전, 오후(AM/PM) | %r | 시분초 (오전/오후 12시간 형식 hh:mm:ss AM/PM) |
| %j | 그해의 몇 번째 일인지 표시(001-366) | %w | 그 주의 몇 번째 일인지 표시(0=일요일, 6=토요일) |
| %W | 주(Monday, Tuesday…) | %a | 줄인 이름(Mon, Tue, Wed, Thu…) |
예제) 현재시간을 구분자 -와 구분자 /를 이용해서 출력하기
Mysql> SELECT DATE_FORMAT(NOW(), '%Y-%m-%d'), DATE_FORMAT(NOW(), '%Y/%m/%d');

예제)
(1) 현재날짜를 요일, 월, 년도 순으로 영어로 출력
(2) 현재날짜를 요일, 월, 년도 순으로 영어로 출력하되 줄임말로!
Mysql> SELECT DATE_FORMAT(NOW(), '%W %M %Y'), DATE_FORMAT(NOW(), '%a %b %Y');

예제) 날짜, 시간, 오전 오후, 요일 다 출력!
Mysql> SELECT DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%s %p %W');

그룹함수
그룹함수란?(통계함수)
- 여러 행 또는 테이블 전체의 행에 대해 함수가 적용되어 하나의 결과값을 가져오는 함수
- GROUP BY절을 이용해 그룹 당 하나의 결과가 주어지도록 그룹화 할 수 있다.
- HAVING절을 사용해 그룹함수를 가지고 조건비교를 할 수 있다.
- COUNT(*)를 제외한 모든 그룹함수는 NULL값을 고려하지 않는다.
- MIN, MAX 그룹함수는 모든 자료형에 대해서 사용할 수 있다.
사용할 DEMO tables:
<emp>

[Group Function의 종류]
1) COUNT
- 검색된 행의 수를 반환(개수를 구하기)
Mysql> SELECT COUNT(empno), COUNT(ename) FROM EMP;
Mysql> SELECT COUNT(empno), COUNT(comm), COUNT(mgr) FROM emp;


-> empno는 14개인데 comm(보너스)는 4개, mgr(매니저)는 13개이다.
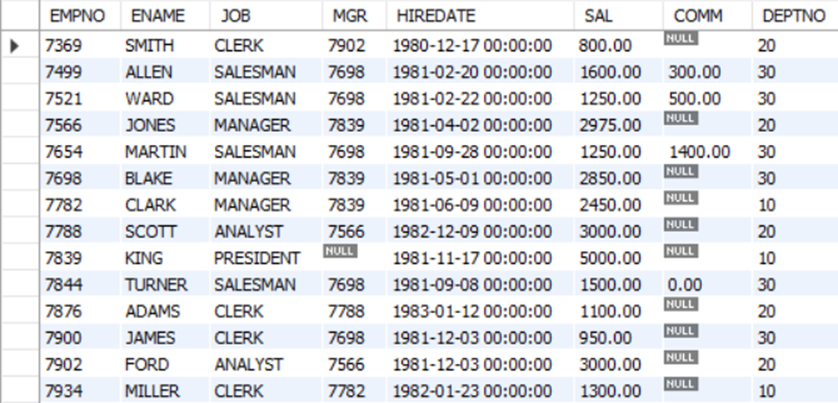
-> NULL값이 있기 때문이다. COUNT에서 NULL 데이터는 개수에서 빠지게 되기 때문에 NULL값이 1개인 MRG는 13개가 출력되고, NULL값이 10개인 COMM은 4개가 출력된다.
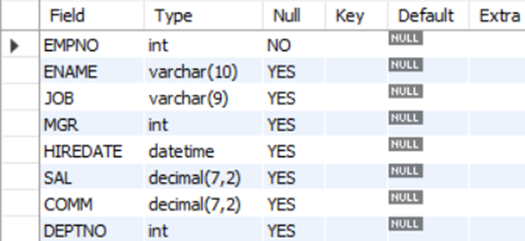
-> DESC emp;를 해서 구조를 보게 되면 EMPNO만 NULL값이 NO로 되어있다.
-> 다른 정보는 없어도 크게 지장이 없지만 사원번호가 없으면 테이블에 데이터가 등록이 안된다는 뜻이다. (NULL이 NO인 경우 반드시 있어야 한다.)
2) MAX, MIN, AVG, SUM
MAX: 제일 큰 값 반환, MIN: 제일 작은 값 반환, AVG: 평균 값 반환(소수점 1자리 이하에서 반올림), SUM: 검색된 컬럼의 합을 반환
예) 급여의 최댓값, 최솟값, 평균, 합계를 구하라
Mysql> SELECT MAX(sal), MIN(sal), AVG(sal), SUM(sal) FROM emp;

[Group by절과 Having절]
1) GROUP BY절
- 특정한 컬럼의 데이터들을 다른 데이터들과 비교해 유일한 값에 따라 묶는다.
- Column명을 GROUP함수와 SELECT절에 사용하고자 하는 경우 GROUP BY뒤에 Column명을 추가한다.
예제1) 부서별로 그룹화(부서코드 사용)하여 부서번호, 인원수, 급여의 평균, 급여의 합을 구하여 출력해라
Mysql> SELECT deptno, COUNT(empno), AVG(sal), SUM(sal) FROM emp GROUP BY deptno ORDER BY deptno;
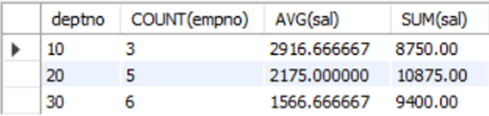
- 그룹함수를 사용하는 필드와 그룹함수로 사용하지 않은 필드는 함께 표기할 수 없어서 그룹함수로 사용하지 않은 필드는 분류기준으로 사용할 수 있다.
-> 여기서 그룹함수를 사용하지 않은 필드이면서 분류기준으로 사용된 것: deptno
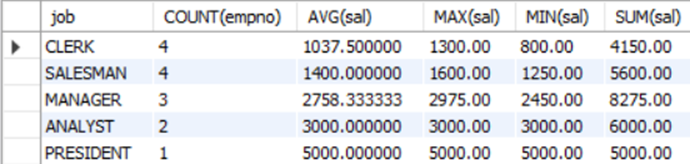
예제2) 업무별로 그룹화하여 업무, 인원수, 평균 급여액, 최고 급여액, 최저 급여액 및 합계를 출력하라.
Mysql> SELECT job, COUNT(empno), AVG(sal), MAX(sal), MIN(sal), SUM(sal) FROM emp GROUP BY job;
2) HAVING절
- WHERE절에 GROUP Function을 사용할 수 없어서 HAVING절은 GROUP함수를 가지고 조건비교를 할 때 사용한다.
- 통계를 구한 데이터를 조건으로 쓰여질 때는 HAVING절 사용(그룹함수에서의 조건문)
- where = 그룹핑 이전 대상, having = 그룹핑 이후 대상
- WHERE -> GROUP BY -> HAVING -> ORDER BY순으로 쿼리문이 와야 한다.
예제1) 사원수가 5명이 넘는 부서의 부서코드와 사원 수를 출력해라
Mysql> SELECT deptno, COUNT(ename) FROM emp GROUP BY deptno HAVING COUNT(empno) > 5;
Mysql> SELECT deptno, COUNT(empno) FROM emp GROUP BY deptno HAVING COUNT(empno) > 5;

예제2) 업무별 급여의 합계, 평균을 구하여 평균이 3000불 이상인 업무를 출력하라.
Mysql> SELECT job , SUM(sal), AVG(sal) FROM emp GROUP BY job HAVING AVG(sal)>=3000;

예제3)업무별 급여의 평균과 보너스(comm)의 평균을 구하라.
Mysql > SELECT job, AVG(sal), AVG(comm) FROM emp GROUP BY job;
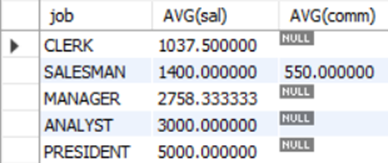
-> sal의 AVG는 맞게 나왔지만 comm의 AVG는 NULL값 때문에 정확한 계산이 나오지 않는다.
-> NULL데이터는 계산에서 제외되기 때문에, NULL데이터를 계산하기 위해서는 NULL을 0으로 바꿔서 계산해야 정확한 계산이 나온다.
Mysql> SELECT SUM(sal), AVG(sal), SUM(comm), AVG(comm) from emp;

-> 오류!(comm의 평균)
Mysql> SELECT SUM(sal), AVG(sal), SUM(comm), AVG(IFNULL(comm,0)) from emp;

-> 만약 comm 컬럼에서 NULL 값이 있다면 0으로 반환해서 계산해라!(IFNULL로 값을 변화시킬 수 있음)
예제4) 보너스(comm)가 있는 사원을 출력하고 그 다음에 보너스(comm)가 있는 사원을 출력하라
Mysql> SELECT * FROM emp WHERE comm IS NULL;
Mysql> SELECT * FROM emp HAVING comm IS NULL;
-> WHERE절을 때에 따라서 사용가능!
-> WHERE절은 기본적인 조건절로서 우선적으로 모든 필드를 조건에 둘 수 있지만 having은 group by 된 이후 특정한 필드로 그룹화 되어진 새로운 테이블에 조건을 줄 수 있다.
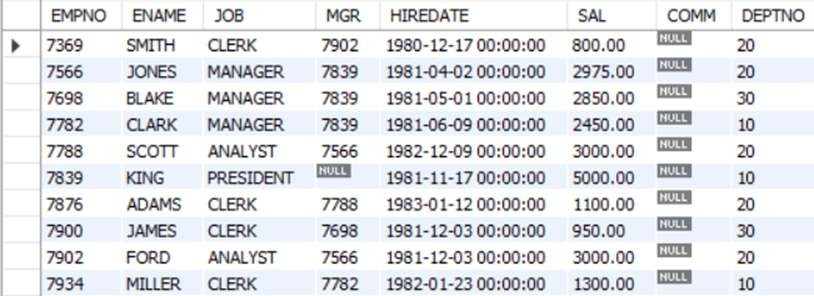
Mysql> SELECT * FROM emp WHERE comm IS NOT NULL;
Mysql> SELECT * FROM emp HAVING comm IS NOT NULL;

예제5) 보너스를 받는 사원의 사원수, 보너스 합, 보너스 평균을 구하라.
Mysql> SELECT count(empno), sum(comm), avg(comm) FROM emp WHERE comm>0;

-> HAVING절은 사용 불가능!!(HAVING절은 보통 GROUP BY 함수와 함께)
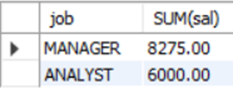
예제6) 전체 월급이 5000을 초과하는 각 업무에 대해서 업무와 월급의 합계를 출력하여라. 단 판매원은 제외하고 월 급여 합계로 내림차순 정렬하여라.
Mysql> SELECT job, SUM(sal) FROM emp WHERE 'salesman' != job GROUP BY job HAVING SUM(sal)>5000 ORDER BY SUM(sal) DESC;
Mysql> SELECT job, SUM(sal) FROM emp WHERE job !='salesman' GROUP BY job HAVING SUM(sal)>5000 ORDER BY SUM(sal) DESC;
'멀티캠퍼스 풀스택 과정 > 데이터베이스' 카테고리의 다른 글
| 데이터베이스2-2 데이터의 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) (0) | 2022.01.19 |
|---|---|
| 데이터베이스2-1 JDBC로 JAVA와 DB의 연동(SELECT문) (0) | 2022.01.19 |
| 데이터베이스1-3 기본 명령어와 SELECT문 및 연산자와 기본문제 (4) | 2022.01.16 |
| 데이터베이스1-2 데이터베이스 모델링과 구조, DBMS 언어(DDL, DML, DCL, TCL) (0) | 2022.01.16 |
| 데이터베이스1-1 DB, DBMS, SQL (0) | 2022.01.16 |



