HashSet - 순서 x 중복 x, 검색

HashSet
- Set인터페이스를 구현한 대표적인 컬렉션 클래스
- (저장)순서를 유지하려면, LinkedHashSet클래스를 사용하면 된다. (Link->연결)
- HashSet의 특징을 이용하면, 컬렉션 내의 중복 요소들을 쉽게 제거 가능
TreeSet
- 범위 검색과 정렬에 유리한 컬렉션 클래스
- HashSet보다 데이터 추가, 삭제에 시간이 더 걸림
HashSet의 주요 메서드
| HashSet( ) | HashSet 객체 생성 |
| HashSet(Collection c) | 주어진 컬렉션을 포함하는 HashSet객체 생성 |
| HashSet(int initialCapacity) | 주어진 값을 초기용량으로 하는 HashSet객체를 생성 |
| HashSet(int initialCapacity, float loadFactor) | 초기용량과 load factor를 지정하는 생성자(언제 초기용량을 만들 것인지) |
| boolean add(Object o) | 새로운 객체를 저장 |
| boolean addAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체들을 추가한다.(합집합) |
| Object clone( ) | HashSet을 복제해서 반환한다.(얕은 복사) |
| boolean remove(Object o) | 지정된 객체를 HashSet에서 삭제(성공하면 true, 실패하면 false) |
| boolean removeAll(Collection c) | 주어진 컬렉션에서 저장된 모든 객체와 동일한 것들을 HashSet에서 모두 삭제한다.(차집합) |
| boolean retianAll(Collection c) | 주어진 컬렉션에 저장된 객체와 동일한 것만 남기고 삭제한다.(교집합) -> 조건부 삭제 |
| void clear( ) | 저장된 모든 객체를 삭제한다. |
| boolean contains(Object o) | 지정된 객체를 포함하고 있는지 알려준다. |
| boolean containsAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체들을 포함하고 있는지 알려준다. |
| Iterator iterator( ) | Iterator를 반환한다. |
| boolean isEmpty( ) | HashSet이 비어있는지 알려준다. |
| int size( ) | 저장된 객체의 개수를 반환한다. |
| Object[ ] to Array( ) | 저장된 객체들을 객체배열의 형태로 반환 |
| Obejct[ ] toArray(Object[ ] a) | 저장된 객체들을 주어진 객체배열(a)에 담는다. |
예제1)
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Ex11_9 {
public static void main(String[] arg) {
Object[] objArr = {"1", new Integer(1), "2", "2", "3", "3", "5", "4", "4", "4"};
Set set = new HashSet();
for(int i=0;i<objArr.length;i++) {
System.out.println(objArr[i]+"="+set.add(objArr[i])); // add( )를 이용해서 HashSet에 objArr의 요소들을 저장한다.
}
// HashSet에 저장된 요소들을 출력한다.
System.out.println(set); // [1, 1, 2, 3, 4, 5] 1은 문자열, 다른 1은 숫자
// HashSet에 저장된 요소들을 출력한다.(Iterator이용)
Iterator it = set.iterator();
while(it.hasNext()) { // 읽어올 요소가 없을 때까지 확인
System.out.print(it.next()); // 112345(순서가 다를 수도 있음)
}
}
}
예제2) Hashset 객체를 생성하고, 6개의 난수(1~45)를 저장해서 정렬하기
import java.util.*;
public class Ex11_10 {
public static void main(String[] args) {
Set set = new HashSet();
// set의 크기가 6보다 작은 동안 1~45사이의 난수를 저장
for(int i=0;set.size()<6;i++) {
int num = (int)(Math.random()*45)+1;
set.add(num); // set.add(new Integer(num))이랑 같다.
}
System.out.println(set); // set이 정렬되지 않은 상태로 출력
List li = new LinkedList(set); // (1)LinkedList(Collection c) ArrayList도 가능
Collections.sort(li); // Collections.sort(List list)
System.out.println(li);
}
}(1) 정렬을 하기 위해서는 Collections.sort를 사용해야 한다. set은 sort를 사용할 수 없다. sort의 매개변수로 올 수 있는 것은 List만!(정렬: 순서유지가 되어야 한다, set은 정렬불가)
-> 정렬하기 위해서 Set->List로 형변환한다음에 List를 정렬할 수 있다.
-> (1) Set의 모든 요소를 List에 저장 (2) List를 정렬 (3) List를 출력
예제3)
- HashSet은 객체를 저장하기 전에 기존에 같은 객체가 있는지 확인(list는 순서0, 중복0이지만 set은 순서x, 중복x)이기 때문에
- 같은 객체가 없으면 저장하고, 있으면 저장하지 않는다.
- boolean add(Object o)는 저장할 객체의 equals( )와 hashCode( )를 호출(equals( )와 hashCode( )가 오버라이딩 되어 있어야 중복 검사가 가능함)

-> equals( ), hashCode( )를 상속받아서(Object 클래스에서) 오버라이딩 할 수 있음

if( ! ( obj instatnceof Person) ) return false;
Person tmp = (Person)obj;
obj가 Person의 instance가 아니면 false
obj가 Person의 instance이면 Person으로 형변환(그래야 tmp.name, tmp.age를 사용가능)
return name.equals(tmp.name) && (this.)age == tmp.age;
String iv인 name은 equals( )로, int iv인 age는 대입연산자로 비교!
-> this와 obj를 비교(객체 자신과 매개변수로 지정된 객체를 비교)
return (name+age).hashCode( );
name -> String, age -> int => String + int는 String
-> String클래스가 가지고 있는 hashCode( )
-> 새로운 방식!(Objects 클래스 사용) return Objects.hashCode(name, age);
import java.util.*;
public class Ex11_11 {
public static void main(String[] args) {
Set set = new HashSet();
set.add("abc");
set.add("abc"); // 중복이라 저장안됨.
set.add(new Person("David", 20)); // equals와 hashCode에 의해서 true 반환
set.add(new Person("David", 20)); // 이 코드는 중복이라 false
System.out.println(set); // [abc, David:20]
}
}
// equals()와 hashCode()를 오버라이딩해야 HashSet이 바르게 동작.
// Source -> Generate hashCode() and equals()
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + ":" + age;
}
@Override
public int hashCode() {
// int hash(Object... values); // 가변인자
return Objects.hash(age, name); // 매개변수를 더 넣을 수 있음
}
@Override
public boolean equals(Object obj) {
if(!(obj instanceof Person)) return false;
Person p = (Person)obj;
// (1)나자신(this)의 이름과 나이를 p와 비교
return this.name.equals(p.name) && this.age == p.age;
}
}
예제4) 교집합, 차집합, 합집합 구하기
import java.util.*;
public class Ex11_12 {
public static void main(String args[]) {
HashSet setA = new HashSet();
HashSet setB = new HashSet();
HashSet setHab = new HashSet(); // 합집합
HashSet setKyo = new HashSet(); // 교집합
HashSet setCha = new HashSet(); // 차집합
setA.add("1"); setA.add("2"); setA.add("3");
setA.add("4"); setA.add("5");
System.out.println("A = " + setA); // A = [1, 2, 3, 4, 5]
setB.add("4"); setB.add("5"); setB.add("6");
setB.add("7"); setB.add("8");
System.out.println("B = " + setB); // B = [4, 5, 6, 7, 8]
// (1)교집합
Iterator it = setB.iterator();
while(it.hasNext()) {
Object tmp = it.next();
if(setA.contains(tmp)) // setA에 tmp(SetB)가 있는지? 없으면 false, 출력 xx
setKyo.add(tmp);
}
System.out.println("A 와 B의 교집합은 " + setKyo + "입니다."); // A 와 B의 교집합은 [4, 5]입니다.
// (2)차집합 (A기준으로)
it = setA.iterator();
while(it.hasNext()) {
Object tmp = it.next();
if(!setB.contains(tmp)) // SetB에 있는 요소가 A에 없으면
setCha.add(tmp); // setCha에 넣어주기
}
System.out.println("A 와 B의 차집합은 " + setCha + "입니다."); // A 와 B의 차집합은 [1, 2, 3]입니다.
//
// (3)합집합
it = setA.iterator();
while(it.hasNext()) {
setHab.add(it.next());
}
it = setB.iterator();
while(it.hasNext()) {
setHab.add(it.next());
}
System.out.println("A 와 B의 합집합은 " + setHab + "입니다."); // A 와 B의 합집합은 [1, 2, 3, 4, 5, 6, 7, 8]입니다.
}
}
1) 교집합
setA.retainAll(setB); // 교집합. 공통된 요소만 남기고 삭제
System.out.println("A와 B의 교집합은 " + setA + "입니다."); // A와 B의 교집합은 [4, 5]입니다.
2) 차집합
setA.removeAll(setB); // 차집합. setB와 공통 요소를 제거
System.out.println("A와 B의 차집합은 " + setA + "입니다."); // A와 B의 차집합은 [1, 2, 3]입니다.
3) 합집합
setA.addAll(setB); // 합집합. setB의 모든 요소를 추가(중복 제외)
System.out.println("A 와 B의 합집합은 " + setA + "입니다."); // A 와 B의 합집합은 [1, 2, 3, 4, 5, 6, 7, 8]입니다.
TreeSet - 범위 탐색, 정렬
- 이진 탐색 트리(binary search tree)로 구현. 범위 탐색과 정렬에 유리
- HashSet과 마찬가지로 Set 인터페이스를 구현했으므로 중복을 허용하지 않고, 정렬하고 사용하기 때문에 저장 순서 유지 xx
- 이진 트리는 모든 노드가 최대 2개(0~2개)의 하위 노드를 가짐
- 각 요소(node)가 나무(tree)형태로 연결(LinkedList의 변형)
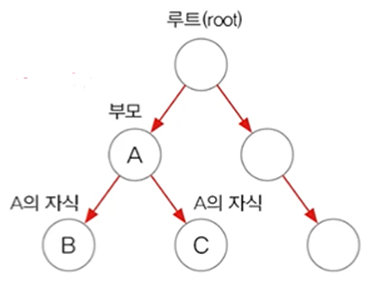
| class TreeNode { TreeNode left; // 왼쪽 자식노드 Object element; // 저장할 객체 TreeNode right; // 오른쪽 자식노드 } |
LinkedList 구조 class Node { Node next; // 다음 요소의 주소를 저장 Object obj; // 데이터를 저장 } |
| TreeSet은 두 개의 요소 | LinkedList는 한 개의 요소만 |
이진 탐색 트리(binary search tree)
- 모든 노드는 최대 두개의 자식노드를 가질 수 있다.
- 왼쪽 자식노드이 값은 부모노드의 값보다 작고 오른쪽자식노드의 값은 부모노드의 값보다 커야한다.
- 노드에 데이터가 많아질수록 추가, 삭제에 시간이 더 걸림(비교 횟수 증가하기 때문)
-> 계속 트리가 커지기 때문에 요소를 저장할 때마다 부모와 계속 대소 비교를 해야함(루트부터)
- 검색(범위검색)과 정렬에 유리하다. (그냥 일반 검색은 HashSet이! TreeSet은 정렬을 해야하기 때문)
- 중복된 값을 저장하지 못한다.
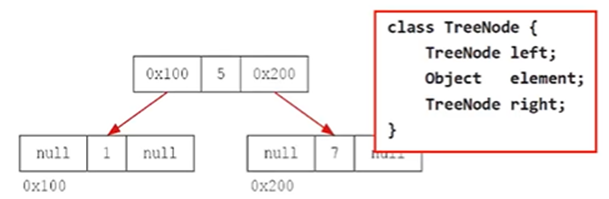
TreeSet - 데이터 저장과정
boolean add(Object o) : Object o는 저장할 객체
-> add( )메서드를 사용하게 되면 HashSet은 중복을 허용하지 않기 때문에 HashSet은 equals( ), hashCode( )로 비교했다.
-TreeSet에 저장되는 객체가 Comparable(compareTo, 기본비교기준)을 구현하던가아니면, TreeSet에게 Comparator(compare)를 제공해서 두 객체를 비교할 방법을 알려줘야 한다. 아니면 TreeSet에 객체를 저장할 떄 예외 발생!
-> 저장실패는 false 반환
* TreeSet에 7,4,9,1,5의 순서로 데이터를 저장하면, 아래의 과정을 거친다. (루트부터 트리를 따라 내려가며 값을 비교, 작으면 왼쪽, 크면 오른쪽에 저장)
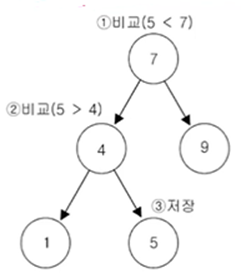
-> 처음에는 비교횟수 0, 그 다음에는 1, 그 다음에는 2 요소를 저장함에 따라 비교횟수도 늘어남
TreeSet의 주요 생성자와 메서드
생성자
| TreeSet( ) | 기본 생성자 |
| TreeSet(Collection c) | 주어진 컬렉션을 저장하는 TreeSet을 생성 |
| TreeSet(Comparator comp) | 주어진 정렬기준으로 정렬하는 TreeSet을 생성 |
-> Comparator comp: 비교기준 제공(필수) 만약 비교기준을 안 주게 되면 저장하는 객체가Comparable을 이용(compareTo( )기본 비교기준)
| Object first( ) (오름차순: 제일 작은 것) | 정렬된 순서에서 첫 번째 객체를 반환한다. |
| Object last( ) (오름차순: 제일 큰 것) | 정렬된 순서에서 마지막 객체를 반환한다. |
| Object ceiling(Object o) (올림) | 지정된 객체와 같은 객체를 반환. 없으면 큰 값을 가진 객체 중 가장 가까운 값의 객체를 반환. 없으면 null |
| ex ceiling(int 45) -> 30, 40, 50 중에서 50 반환 ceiling(int 40) -> 30, 40, 50 중에서 40 반환 |
|
| Object floor(Object o) (버림) | 지정된 객체와 같은 객체를 반환. 없으면 작은 값을 가진 객체 중 가장 가까운 값의 객체를 반환. 없으면 null |
| Object higher(Object o) | 지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null |
| ex) higher(int 40) -> 30, 40, 50 증에서 50 반환 | |
| Object lower(Object o) | 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null |
| SortedSet subSet(Object fromElement, Object toElement) | 범위 검색(fromElement와 toElement사이)의 결과를 반환한다.(끝 범위인 toElement는 범위에 포함되지 않음) from ~ to 어디부터 어디까지 |
| ex) subset(int 20, int 50) -> 30, 40, 50 중에서 30과 40 반환 | |
| SortedSet headSet(Object toElement) | 지정된 객체보다 작은 값의 객체들을 반환한다. |
| SortedSet tailSet(Object fromElement) | 지정된 객체보다 큰 값의 객체를 반환한다. |
add( ), remove( ), size( ), isEmpty( ), iterator( )는 이미 Collections 인터페이스가 갖고 있기 때문에 여기선 생략
예제1)
import java.util.*;
public class Ex11_13 {
public static void main(String[] args) {
Set set = new TreeSet(); // 범위 검색, 정렬에 유리함, HashSet은 정렬필요
for(int i=0; set.size()<6; i++) {
int num = (int)(Math.random()*45)+1;
set.add(num); // set.add(new Integer(num));
}
System.out.println(set); // 정렬 필요 없음 [13, 20, 34, 36, 37, 45]
}
}
예제2)
import java.util.*;
public class Ex11_13 {
public static void main(String[] args) {
Set set = new TreeSet(); // 범위 검색, 정렬에 유리함, HashSet은 정렬필요
for(int i=0; set.size()<6; i++) {
int num = (int)(Math.random()*45)+1;
set.add(num); // set.add(new Integer(num));
}
System.out.println(set); // 정렬 필요 없음 [13, 20, 34, 36, 37, 45]
}
}
<출력값>
[Car, abc, alien, bat, car, dZZZZ, dance, disc, dzzzz, elephant, elevator, fan, flower]
range search: from bto d
result1 : [bat, car]
result2 : [bat, car, dZZZZ, dance, disc]
예제3)
TreeSet – 범위 검색 subSet( ), headSet( ), tailSet( )

import java.util.TreeSet;
public class Ex11_15 {
public static void main(String[] args) {
TreeSet set = new TreeSet(); // Set에는 headSet, tailSet, subSet이 존재하지 않기 때문에 Set 사용 xx
int[] score = {80, 95, 50, 35, 45, 65, 10, 100};
for(int i=0; i<score.length; i++) { // 배열에 있는 값은 treeSet에 저장
set.add(new Integer(score[i])); //set.add(score[i]));
}
System.out.println("50보다 작은 값: " + set.headSet(new Integer(50))); // 50보다 작은 값: [10, 35, 45]
System.out.println("50보다 큰 값: " + set.tailSet(new Integer(50))); // 50보다 큰 값: [50, 65, 80, 95, 100]
System.out.println("40과 95사에이 있는 값: " + set.subSet(40, 95)); // 40과 95사에이 있는 값: [45, 50, 65, 80]
}
}
* 알면 좋은 것*
트리 순회(tree traversal)
- 이진 트리의 모든 노드를 한번씩 읽는 것
- 전위, 중위, 후위 순회법이 있고, 중위 순회하면 오름차순으로 정렬된다.
'멀티캠퍼스 풀스택 과정 > Java의 정석' 카테고리의 다른 글
| 자바의 정석9-1 지네릭스 (0) | 2022.01.12 |
|---|---|
| 자바의 정석8-6 HashMap, Hashtable, Collections 요약 (0) | 2022.01.10 |
| 자바의 정석8-4 Arrays, Comparator와 Comparable (0) | 2022.01.10 |
| 자바의 정석8-3 스택과 큐/Iterator, ListIterator, Enumeration (0) | 2022.01.10 |
| 자바의 정석8-2 ArrayList, LinkedList (0) | 2022.01.08 |



